
ElasticSearch基本使用-应用实例
编辑es-header与postman基于索引的基本操作
可以在复合查询部分使用restful风格的请求

创建索引
在es-head创建索引
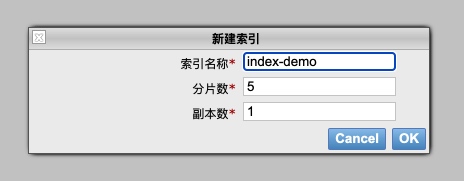
REST请求创建索引: PUT请求 /{index-name};
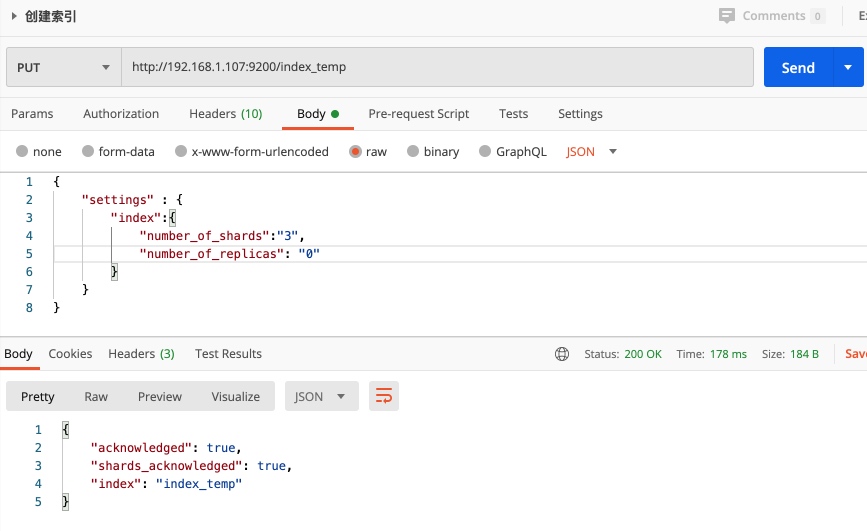
{
"settings" : {
"index":{
"number_of_shards":"3",
"number_of_replicas": "0"
}
}
}
删除索引
Rest请求删除索引 : Delete请求, {es-host}/{index-name}

查看索引信息
查看指定索引信息: GET请求 {es-host}/{index-name}

查看所有索引列表信息 GET请求,{es-host}/_cat/indices;如果需要查看表头使用/_cat/indices?v
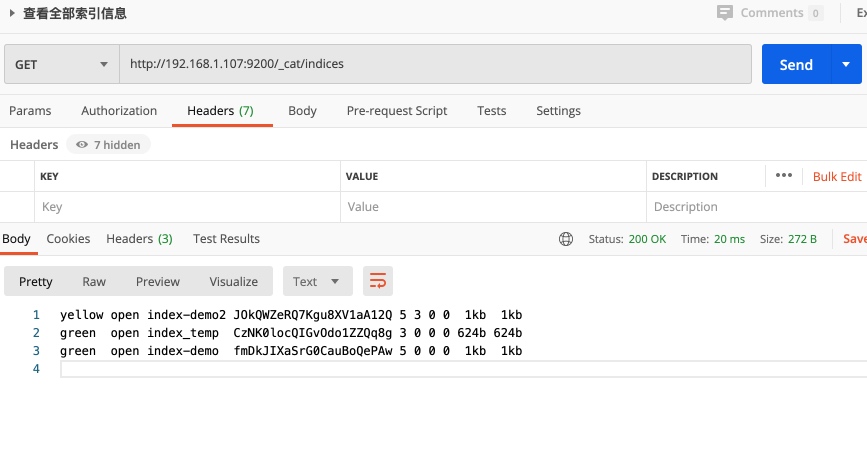
集群健康值:
es-head查看健康值
主分片全部可用,但是因为测试部署单实例集群,副本没有被分配不可用,健康值黄色警告;
集群健康说明文档

status 字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
- green 所有的主分片和副本分片都正常运行。
- yellow 所有的主分片都正常运行,但不是所有的副本分片都正常运行。
- red 有主分片没能正常运行。
rest请求获取健康值 请求路由:/_cluster/health

mapping自定义创建映射;
创建索引的同时创建mapping: PUT请求 /index_mapping;
// 设置对应的索引mapping映射,
{
"mappings": {
"properties":{
"realname": {
"type":"text",
"index":true
},
"username": {
"type":"keyword",
"index":false
}
}
}
}

索引分词概念
index:默认true,设置为false的话,那么这个字段就不会被索引
引用官文:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-index.html
index
The index option controls whether field values are indexed. It accepts true or false and defaults to true. Fields that are not indexed are not queryable.
查看分词效果
- 默认的分词器不支持中文,会将中文全部拆为一个一个字,并且会将英文大写转换为小写;
- 如果属性值的index设置为false则不会进行分词索引;
GET /index_mapping/_analyze
{
"field": "realname",
"text": "I am a good Programmer"
}

修改索引的mapping属性
- 需要注意的是,索引字段属性一旦建立是不可以删除的,所以需要预先设计好;
- 但是可以新增,可以允许重复设置相同的值,但是已存在的同参数值设置不一样会报错
illegal_argument_exception
POST /index-name/_mapping
{
"properties": {
"name": {
"type": "long"
}
}
}

为已存在的索引创建或创建mappings,支持多种数据类型设置
POST /index-name/_mapping
{
"properties": {
"id": {
"type": "long"
},
"age": {
"type": "integer"
},
"nickname": {
"type": "keyword"
},
"money1": {
"type": "float"
},
"money2": {
"type": "double"
},
"sex": {
"type": "byte"
},
"score": {
"type": "short"
},
"is_teenager": {
"type": "boolean"
},
"birthday": {
"type": "date"
},
"relationship": {
"type": "object"
}
}
}
注:某个属性一旦被建立,就不能修改了,但是可以新增额外属性
主要数据类型
- text, keyword, string
- long, integer, short, byte
- double, float
- boolean
- date
- object
- 数组不能混,数组的元素类型必须一致,但是支持数组中嵌套放入object
字符串
- text:文字类需要被分词被倒排索引的内容,比如
商品名称,商品详情,商品介绍,使用text。 - keyword:不会被分词,不会被倒排索引,直接匹配搜索,比如
订单状态,用户qq,微信号,手机号等,这些精确匹配,无需分词。
文档基本操作
添加文档数据自动映射 : 如果索引不存在自动创建,按照传入的json格式自动映射;
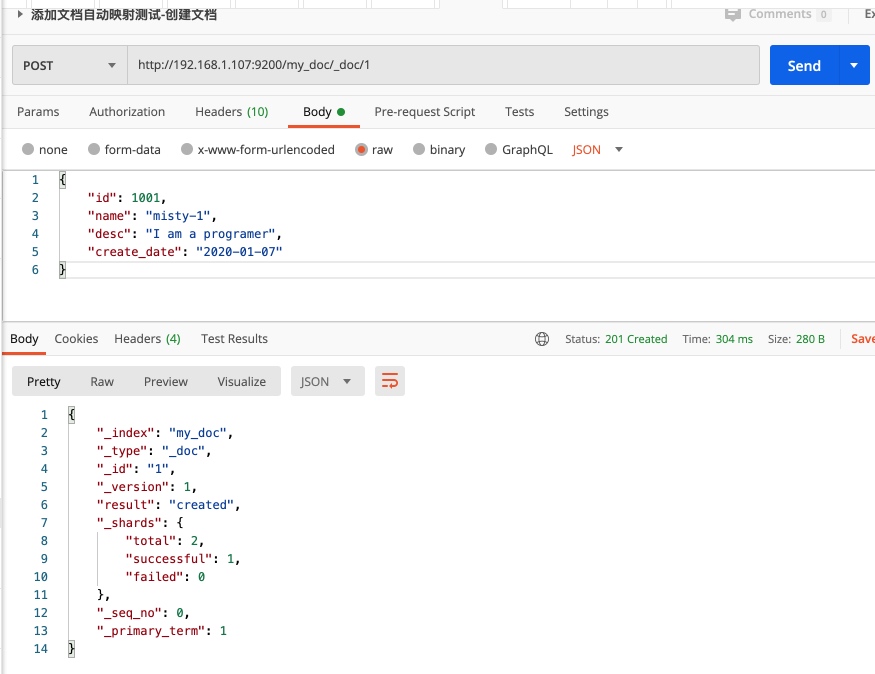
REST请求添加文档数据 POST请求:/index-name/_doc/{文档库id}
POST /my_doc/_doc/{文档索引id} (索引的id是文档库的id,而不是业务id,可以自行指定,如果不传入则自动生成)
{
"id": 1001,
"name": "misty-7",
"desc": "I am a UI designer",
"create_date": "2020-01-07"
}
数据查看分析
_id是文档库的id,可以自行设置,可以和数据源id保持一致,如果不设置会自动生成;id是业务id,数据源的id可以来自于数据库_type新版本文档是_doc,早期的版本type有逻辑分类的意思,7.X之后进行了移除,一般写为_doc- 注意: 如果索引没有手动建立mapping,那么当插入文档数据的时候,会根据文档类型自动设置属性类型,这个就是es的动态映射,帮我们在index索引库中建立数据结构相关的配置信息;
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
- "field":{"type":"keyword"}对一个字段设置多种索引模式,使用text类型作为全文检索,也可以使用keyword类型做聚合和排序;
- "ignore_above":256:设置字段索引和存储的长度最大值,超过则会被忽略;
通过es-head查询检索数据
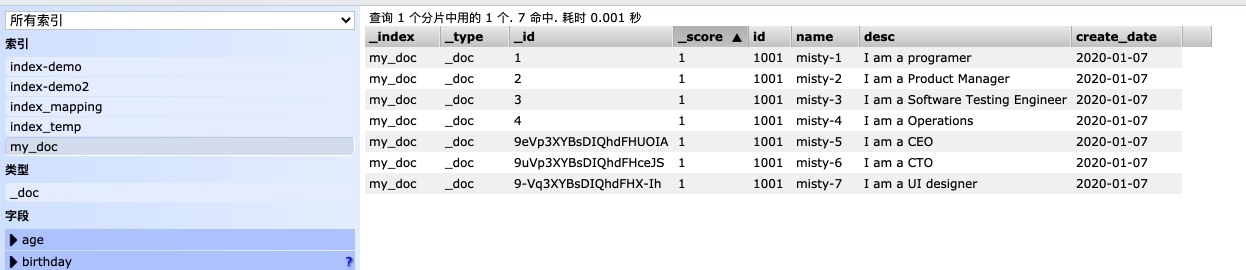
如上图可以在对应字段部分输入关键字进行搜索显示数据;
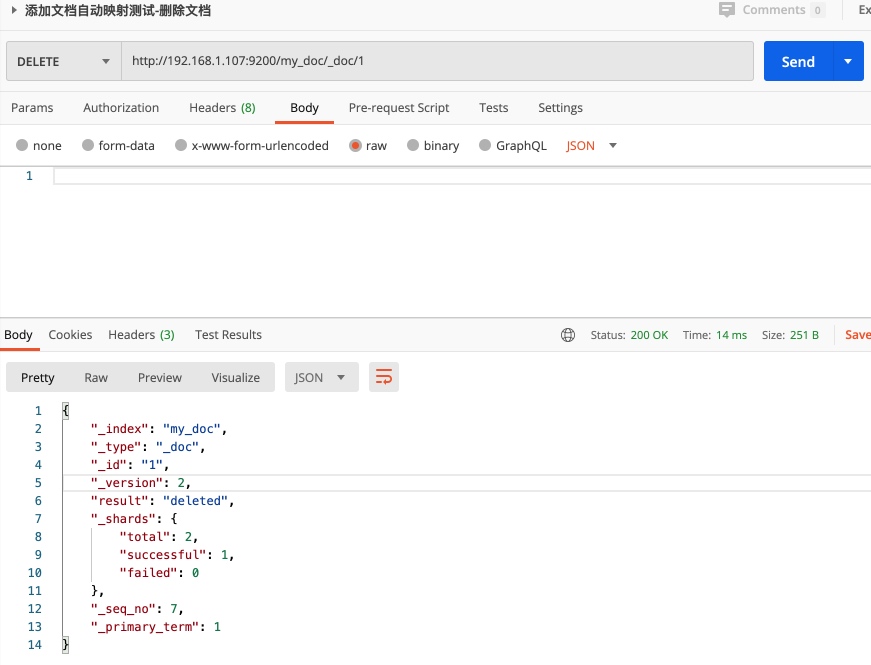
文档内容删除 : DELETE请求:/index-name/_doc/{文档id}
文档删除不是立即删除,每次修改会进行版本累加,不管操作成功失败都会进行version累加;,实际上是逻辑删除,给一个删除标识符,只有磁盘空间不足才会对标记删除的内容进行清理; 如果删除成功那么result为deleted否则为not_found
文档内容修改(局部)
POST请求: /index-name/_doc/{文档id}/_update

文档内容全覆盖修改(全部内容替换)
PUT请求: /index-name/_doc/{文档id};实测post和put类似,如果存在则替换,不存在则进行创建

文档的基本操作-查询
常规查询:
GET /index-name/_doc/1 查询指定id的结果
GET /index-name/_doc/_search 查询全部的文档
查询结果
## 查询指定id的文档内容
{
"_index": "my_doc",
"_type": "_doc",
"_id": "112",
"_version": 1,
"_seq_no": 27,
"_primary_term": 1,
"found": true,
"_source": {
"id": 1001,
"name": "misty-7",
"desc": "I am a UI designer",
"create_date": "2020-01-07"
}
}
## 查询全部结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 9,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_doc",
"_type": "_doc",
"_id": "3",
"_score": 1.0,
"_source": {
"id": 1001,
"name": "misty-3",
"desc": "I am a Software Testing Engineer",
"create_date": "2020-01-07"
}
},
{
"_index": "my_doc",
"_type": "_doc",
"_id": "4",
"_score": 1.0,
"_source": {
"id": 1001,
"name": "misty-4",
"desc": "I am a Operations",
"create_date": "2020-01-07"
}
},
{
"_index": "my_doc",
"_type": "_doc",
"_id": "9uVp3XYBsDIQhdFHceJS",
"_score": 1.0,
"_source": {
"id": 1001,
"name": "misty-6",
"desc": "I am a CTO",
"create_date": "2020-01-07"
}
},
{
"_index": "my_doc",
"_type": "_doc",
"_id": "9-Vq3XYBsDIQhdFHX-Ih",
"_score": 1.0,
"_source": {
"id": 1001,
"name": "misty-7",
"desc": "I am a UI designer",
"create_date": "2020-01-07"
}
},
{
"_index": "my_doc",
"_type": "_doc",
"_id": "9eVp3XYBsDIQhdFHUOIA",
"_score": 1.0,
"_source": {
"id": 1001,
"name": "misty-5",
"desc": "I am a CEO",
"create_date": "2020-01-07"
}
},
{
"_index": "my_doc",
"_type": "_doc",
"_id": "6",
"_score": 1.0,
"_source": {
"id": 1001,
"name": "misty-7",
"desc": "I am a UI designer",
"create_date": "2020-01-07"
}
},
{
"_index": "my_doc",
"_type": "_doc",
"_id": "2",
"_score": 1.0,
"_source": {
"id": 1001,
"name": "misty-7",
"desc": "I am a UI designer",
"create_date": "2020-01-07"
}
},
{
"_index": "my_doc",
"_type": "_doc",
"_id": "11",
"_score": 1.0,
"_source": {
"id": 1001,
"name": "misty-7",
"desc": "I am a UI designer",
"create_date": "2020-01-07"
}
},
{
"_index": "my_doc",
"_type": "_doc",
"_id": "112",
"_score": 1.0,
"_source": {
"id": 1001,
"name": "misty-7",
"desc": "I am a UI designer",
"create_date": "2020-01-07"
}
}
]
}
}


元数据分析
- _index :文档数据所属那个索引,理解为数据库的某张表即可
- _type: 文档数据属于那个类型,新版本用
_doc - _id:文档数据的唯一标识,类似于数据库的某个表的主键,可以自动生成(创建的时候不指定)或者手动指定id
- _score: 查询相关度,是否契合用户匹配,分数越高用户的搜索体验越高
- _version:版本号
- _source:文档数据,json格式
定制结果集
可以对响应的数据_source的内容进行限制,适合响应字段很多的场景,仅返回指定的数据
GET /index-name/_doc/1?_source=id,name
GET /index-name/_doc/_search?_source=id,name
判断文档是否存在
其实也可以使用GET请求看响应的数据是否正常来判断,但是在数据量很大的时候不适用,响应效率比较低,可以使用head请求的响应码来判断是否存在,200代表文档存在,404代表文档不存在;
HEAD /index-name/_doc/1
文档乐观锁控制if_seq_no与if_primary_term
- 新版本不支持version参数来实现乐观锁控制
# 插入新数据
POST /my_doc/_doc
{
"id": 10012,
"name": "misty-7",
"desc": "I am a UI designer",
"create_date": "2020-01-07"
}
# 修改数据
POST /my_doc/_doc/{_id}/_update
{
"doc" :{
"name":"misty-1"
}
}
更新或者插入新数据的时候_version和_seq_no都会进行累加;
{
"_index": "my_doc",
"_type": "_doc",
"_id": "112",
"_version": 7,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 33,
"_primary_term": 1
}
两个客户端操作同一个文档数据,_version都携带一样的值
## 操作1
POST /my_doc/_doc/{_id}/_update?if_seq_no={数值}&if_primary_term={数值}
{
"doc" :{
"name":"misty-1"
}
}
## 操作2
POST /my_doc/_doc/{_id}/_update?if_seq_no={数值}&if_primary_term={数值}
{
"doc" :{
"name":"misty-2"
}
}
# 如上操作会出现"[112]: version conflict....,错误
应该将文档当前的版本号作为参数提交,如果成功则返回,失败返回error数据;
实测:如果局部更新没有变化的话,
"result": "noop"_version和_seq_no不会进行累加
版本元数据
一个是累加的和version类似,一个是集群中的分配的编号,sequence number and primary term
- _seq_no: 文档版本号,作用同_version(相当于学生编号,每个班级的班主任为学生分配编号,效率要比学校教务处分配来的更加高效,管理起来也方便)
- _primary_term: 文档所在位置(相当于班级)
分词与内置分词器
什么是分词?
把文本转化成一个个单词,分词称之为analysis,es默认只对英文语句做分词,,中文不支持,每个中文会被拆分为独立的个体;
使用分词分析文本
POST /_analyze
{
"analyzer":"standard",
"text":"I am a programer"
}
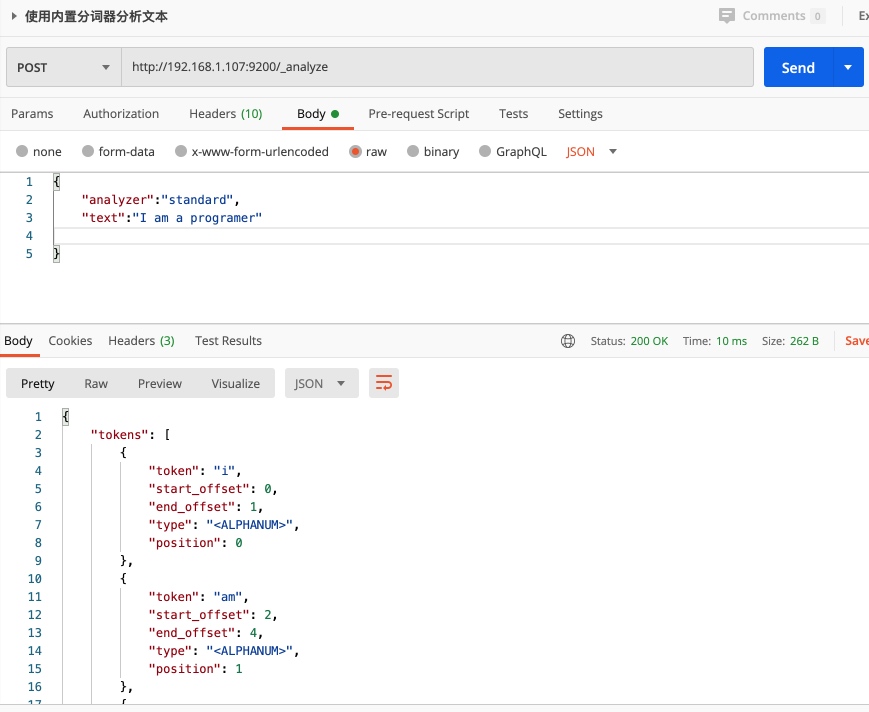
对现有索引的属性进行分词分析
POST /my_doc/_analyze
{
"analyzer":"standard",
"field":"desc"
"text":"I am a programer,My name is Misty,I am a Super Hero. I don't like the study."
}

ES内置分词器
- standard : 默认分词,单词会被拆分,大小会转换为大小写;
- simple: 按照非字母分词,大写转换为小写;
- whitespace :按照空格分词,忽略大小写;
- stop: 出去无意义的单词,比如:
the/a/an/is... - keyword: 不做分词,把整个文本作为一个单独的关键词;
使用示例:
# 将name作为单独的关键词,不做分词
POST /my_doc/_analyze
{
"analyzer":"keyword",
"field":"name"
"text":"I am a programer"
}
- 0
- 0
-
分享